Overview
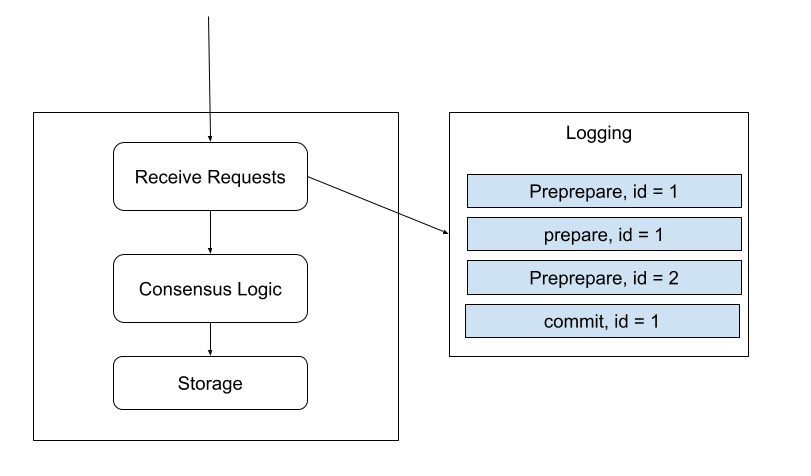
Logging is used to help ResilientDB to recover its local state after restarting. The state can be the one before it is shut down or the state from other replicas. When ResilientDB receives a request related to the consensus logic, it will be written to a log file by appending to the tail to guarantee written order. Requests in the log file will be the same as the requests received from the network. If the system uses multi-threads to process the requests, the written order is random but it guarantees that requests will be persistent to the disk before processing. Thus, if a system restarts and redo all the requests from the log file, it will produce the same state.
Storage Restriction
Since ResilientDB will redo the requests from the log, the storage needs to handle repeated requests. At least, it can go to the same state if producing the same operations from some points. For example, for the raw key-value service which provides only Get and Set interfaces. No matter from which point to redo the requests, as long as it is the logging point before its last update, it will reach the same state since all the Set requests will overwrite the previous records and only the last set will be kept.
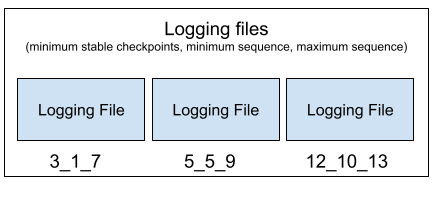
Checkpoint Files
To reduce the size of the log file, it will be split into some small files. In most of the consensus protocols that support checkpoints, they will generate some stable checkpoints which indicates that the system can remove the logs before these checkpoints. In ResilientDB, a stable checkpoint is a sequence number that all the requests earlier than that number have been committed. Thus, the redo process can start from a stable checkpoint.
As the requests are out of order in the log files, each file will save the request information including the stable checkpoint, the minimum and the maximum sequence numbers of the requests in the files in their file names except the latest active one.
When loading the requests starting from a stable checkpoint S, start from the earliest file whose maximum sequence of the requests is less than S.
Consistency to Storage
Starting from a middle stable checkpoint could not guarantee the storage has executed all the requests before the checkpoint as the stable checkpoint generation and the storage execution are isolated.
To solve this problem, we switch to a new file only if the storage has executed all the requests whose sequences are less than the smallest stable checkpoint in the file. That means that, in one log file, there will be many stable checkpoints. We only consider the smallest one. In other words, we guarantee that when we finish log file A whose minimum stable checkpoint is X, all the requests with sequence numbers less than X have been committed.
So it is safe to redo the requests starting from A. However, because some requests will fall into the files before A, we need to find the starting log file using the maximum sequence number discussed above.