In this article, we present a comprehensive introduction to the Geo-Scale Byzantine Fault-Tolerant consensus protocol (GeoBFT) through the lens of the NexRes codebase. We will illustrate the algorithm of inter-cluster sharing and remote view-change of the protocol, and how to implement it on NexRes. We will also show the performance experiment results we got for GeoBFT on NexRes.
The challenges in Geo-scale blockchains
The traditional blockchain protocols like PBFT1, rely on a single primary replica to coordinate all consensus decisions, and require a vast amount of global communication between all pairs of replicas, hence, they often attain low throughput, especially when the replicas are spread across a wide-area network or geographically large distances.
As the following figure shows, the global message latencies are at least 33-270 times higher than local latencies, while the maximum throughput is 10-151 times lower, both implying that the communication between regions is much more costly than communications within regions.

Figure 1. Real-world inter- and intra-cluster communication costs in terms of the ping round-trip times (which determines latency) and bandwidth (which determines throughput). These measurements are taken in Google Cloud using clusters of n1 machines (replicas) that are deployed in six different regions.
Geo-Scale Byzantine Fault-Tolerant consensus protocol (GeoBFT)
Here we present GeoBFT that uses topological information to group all replicas in a single region into a single cluster2. GeoBFT assigns each client to a single cluster, and it operates in rounds, in each round, every cluster will be able to propose a single client request for execution. Each round consists of the three steps sketched in Figure 2: local replication, global sharing, and ordering and execution, which we further detail next.

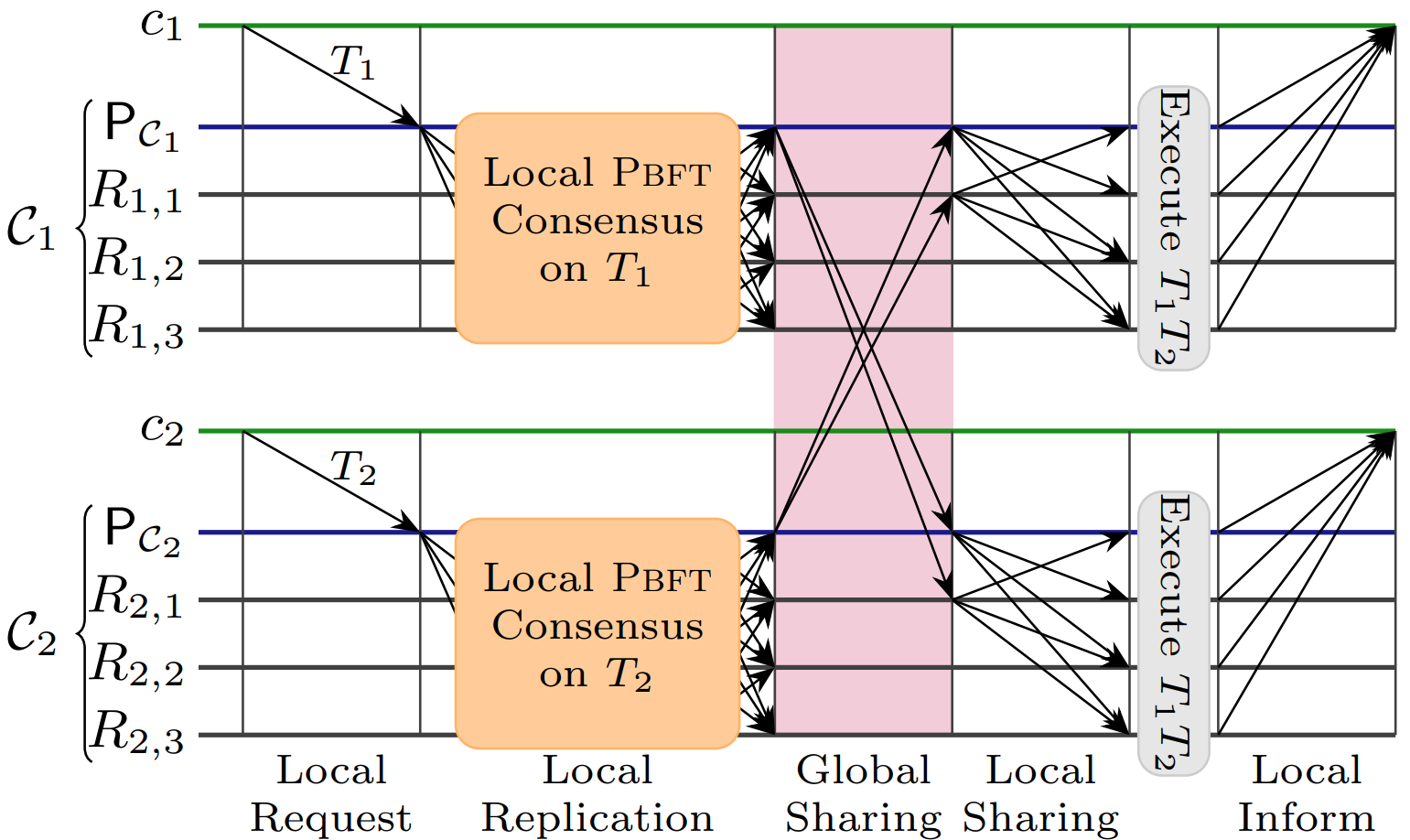
Figure 2. Steps in a round of the GeoBFT protocol.
Local Replication
In the first step of GeoBFT, each round starts with each cluster replicating a client request T, to do so, GeoBFT relies on PBFT. In addition, when each non-faulty replica commits the proposed request, it will also construct a commit certificate $\langle T\rangle_{C}$ consisting of the client request and n-f > 2f identical COMMIT messages for $\langle T\rangle_{P_{C}}$ signed by distinct replicas. The following graph shows the normal-case workflow of round $\rho$ of PBFT within a cluster $C$: a client $c$ requests transaction $T$, the primary $P_{C}$ proposes this request to all local replicas, which prepare and commit this proposal, and, finally, all replicas can construct a commit certificate.
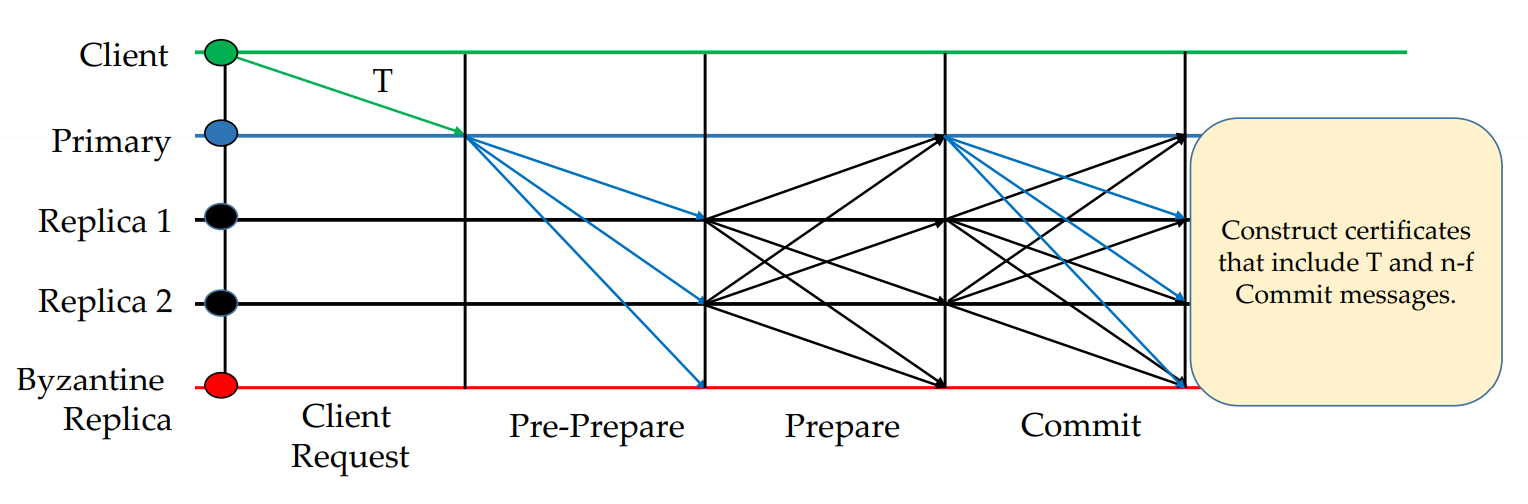
Figure 3. The normal-case working of round ρ of PBFT within a cluster C
Global Sharing
Once a cluster has completed local replication of a client request, it proceeds with the second step: sharing the client request with all other clusters. After $C$ reaches local consensus on client request $\langle T\rangle_{P_{C}}$ in round $\rho$—enabling the construction of the commit certificate $[\langle T \rangle_{P_{C}}, \rho]$ that proves local consensus— $C$ needs to exchange this client request and the accompanying proof with all other clusters. The following graphs show the global sharing protocol used by $C_{1}$ to send $m := (\langle T \rangle_{P_{c}}, [ \langle T \rangle_{P_{c}}, \rho ])$ to $C_{2}$ and the pseudo-code of this protocol, which we will illustrate next.
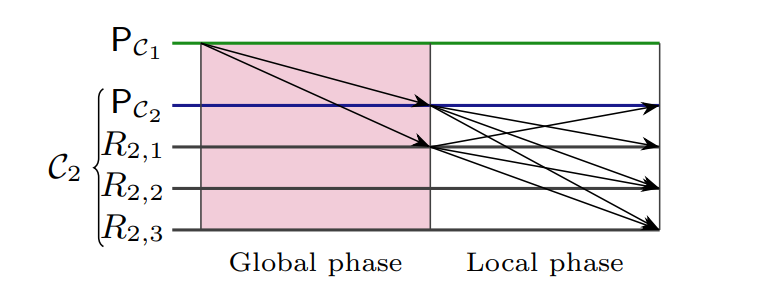
Figure 4. The normal-case working of the global sharing protocol.

Figure 5. Pseudo Code of the normal-case global sharing protocol.
Let $m := (\langle T \rangle_{P_{c}}, [ \langle T \rangle_{P_{c}}, \rho ])$ be the message that some replica in cluster $C_{1}$ needs to send to some replicas $C_{2}$.
In the global phase, the primary $P_{C_{1}}$ sends $m$ to $f+1$ replicas in $C_{2}$. In the local phase, each non-faulty replica in $C_2$ that receives a well-formed m forwards m to all replicas in its cluster $C_{2}$.
There are two cases in which replicas in $C_{2}$ do not receive $m$ from $C_{1}$: either $P_{C_{1}}$ is faulty and did not send $m$ to $f+1$ replicas in $P_{C_{2}}$, or communication is unreliable, and messages are delayed or lost. In both cases, non-faulty replicas in $C_{2}$ initiate remote view-change to force primary replacement in $C_{1}$.
Remote View-Change
To recover from any failures, we provide a remote view-change protocol. To simplify the presentation, we focus on the case in which the primary of cluster $C_{1}$ fails to send $m := (\langle T \rangle_{P_{c}}, [ \langle T \rangle_{P_{c}}, \rho ])$ to replicas of $P_{C_{2}}$. As the following graph describes, our remote view-change protocol consists of four phases, which we detail next. This protocol is triggered when a cluster $C_{2}$ ∈ S expects a message from $C_{1}$ ∈ S, but does not receive this message in time.
- First, non-faulty replicas in cluster $C_{2}$ detect the failure of the current primary $P_{C_{1}}$ of ${C_{1}}$ to send m. Note that although the replicas in $C_{2}$ have no information about the contents of message m, they are awaiting the arrival of a well-formed message m from $C_{1}$ in round $\rho$.
- Second, the non-faulty replicas in $C_{2}$ initiate agreement on failure detection.
- Third, after reaching an agreement, the replicas in $C_{2}$ send their request for a remote view-change to the replicas in $C_{1}$ in a reliable manner.
- In the fourth and last phase, the non-faulty replicas in $C_{1}$ trigger a local view-change, replace $P_{C_{1}}$ , and instruct the new primary to resume global sharing with $C_{2}$.
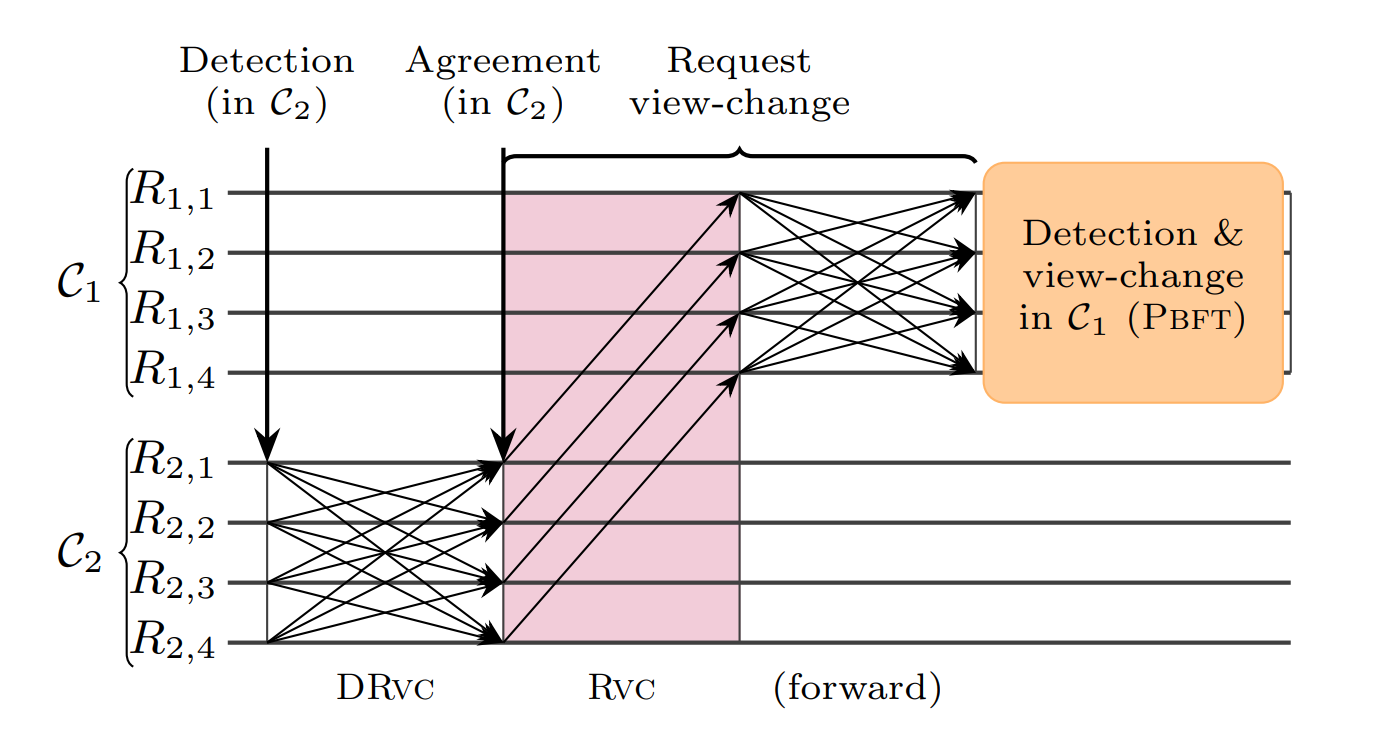
Figure 6. The remote view-change protocol of GeoBFT.
Ordering and Execution
Once replicas of a cluster have chosen a client request for execution and have received all client requests chosen by other clusters, the final step is ordering and executing these client requests. In specific, in round $\rho$, any non-faulty replica that has valid requests from all clusters can move ahead and execute these requests. To put these client requests in a unique order, execute them, and inform the clients of the outcome, GeoBFT simply uses a pre-defined ordering on the clusters. For example, each replica executes the transactions in the order $[T_{1}, . . . , T_{z}]$. Once the execution is complete, each replica $R \in C_{i}, 1 \leq i \leq z$, informs the client $c_{i}$ of any outcome.
Implementation
Now we will give a brief overview of the implementation of the GeoBFT protocol in NexRes. To implement GeoBFT on NexRes, we will need to add a few modules: Local Executor, Global Executor, GeoBFT Consensus Service, and also adjust the Configuration, which we will introduce next. Below is the normal-case working graph of GeoBFT on NexRes.
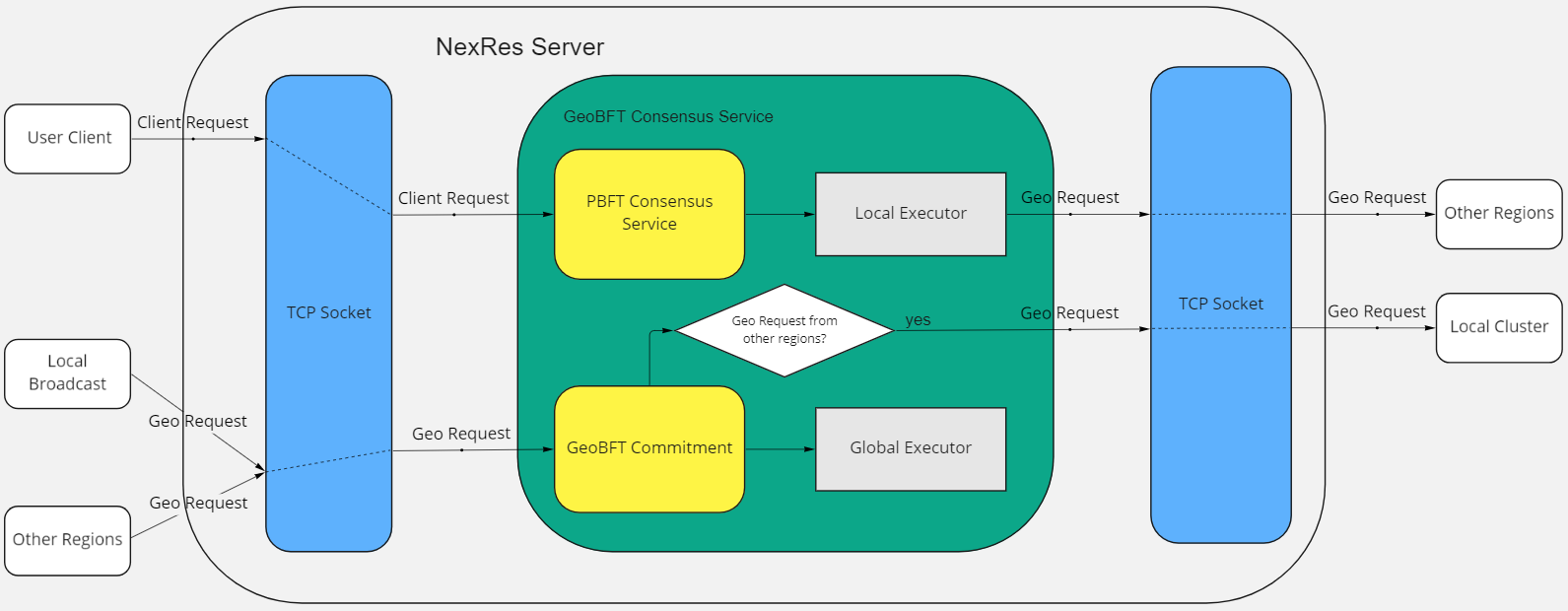
Figure 7. The normal-case working of GeoBFT on NexRes
Configuration
To implement GeoBFT on NexRes, we need to first add a few fields in the configuration file, which specify the timeout for remote view-change, and the flag that indicates whether the local view-change is enabled.
{
region: [
{
replicaInfo: {
id:
ip:
port:
},
regionId: 1
}
],
selfRegionId: 1,
rvc_timeout_ms: 60000, # Timeout for Remote View-Change
enable_viewchange: true # View-Change Flag
}
Local Executor
After committing a local client request at the end of PBFT, the local executor will construct the commit certificate which is of TYPE_GEO_REQUEST, here we call it geo_request. The primary replica will be responsible for sending out the geo_request to every other cluster in the system. Specifically, for each round, the same geo_request will only need to be sent to f+1 replicas in each cluster.
void GeoTransactionExecutor::SendBatchGeoMessage(
const std::vector<std::unique_ptr<Request>>& batch_geo_request) {
// Construct geo_request
std::unique_ptr<Request> geo_request = resdb::NewRequest(
Request::TYPE_GEO_REQUEST, Request(), config_.GetSelfInfo().id(),
config_.GetConfigData().self_region_id());
... // set sequence number, proxy id, hash value, data in geo_request
// Only for primary node, send out geo_request to other regions.
if (config_.GetSelfInfo().id() == system_info_->GetPrimaryId()) {
for (const auto& region : config_data.region()) {
if (region.region_id() == config_data.self_region_id()) continue;
int max_faulty = (region.replica_info_size() - 1) / 3; // maximum number of faulty replicas in this region
int num_request_sent = 0;
for (const auto& replica : region.replica_info()) {
if (num_request_sent > max_faulty) {
break;
}
LOG(ERROR) << "send batch_geo_request to node " << replica.id();
int ret = replica_client_->SendBatchMessage(batch_geo_request, replica); // send to f + 1 replicas in the region
if (ret >= 0) {
num_request_sent++;
}
}
}
}
}
Global Executor
After receiving a geo_request from another region, push it into order_queue_, which is storing the transactions that are not yet ordered. The global executor will constantly pop out geo_request from order_queue_, and add it to execute_map_, which is storing the transactions that are waiting to be executed by order. Then, the global executor will find the next transaction to execute in the execute_map_ according to the current round $\rho$. We use a thread to keep this ordering and execution process going.
std::map<std::pair<uint64_t, int>, std::unique_ptr<Request>> execute_map_;
std::thread order_thread_ = std::thread(&GeoGlobalExecutor::OrderRound, this);
int GeoGlobalExecutor::OrderGeoRequest(std::unique_ptr<Request> request) {
order_queue_.Push(std::move(request));
return 0;
}
void GeoGlobalExecutor::AddData() {
auto request = order_queue_.Pop(); // Pop geo_request from order_queue_
if (request == nullptr) {
return;
}
uint64_t seq_num = request->seq();
int region_id = request->region_info().region_id();
execute_map_[std::make_pair(seq_num, region_id)] = std::move(request); // add geo_request to execute_map_
}
void GeoGlobalExecutor::OrderRound() {
while (!IsStop()) {
AddData(); // Pop geo_request from order_queue_, add it to execute_map_
while (!IsStop()) {
std::unique_ptr<Request> seq_map = GetNextMap(); // Get next geo_request to execute in the execute_map_
if (seq_map == nullptr) {
break;
}
Execute(std::move(seq_map)); // Execute the geo_request and reset the timer for remote view change.
}
}
}
The global executor also has $\mathcal{n-1}$ timers to trigger remote view-change in $\mathcal{n-1}$ other regions. Let $\mathcal{R} \in \mathcal{C_{1}}$ be the replica we are looking at. Upon receiving a geo_request from another region, the global executor will need to reset the timer for that region. When the timeout function is triggered, $\mathcal{R}$ will broadcast a drvc_request locally. After receiving $\mathcal{f+1}$ distinct drvc_request from other replicas in local cluster, $\mathcal{R}$ will also start to broadcast a drvc_request locally. After receiving $\mathcal{n-f}$ distinct drvc_request from other replicas in the local cluster, $\mathcal{R}$ will start to send a new type of request-rvc_request to $\mathcal{Q} \in \mathcal{C_{2}}$ with $id(\mathcal{Q})=id(\mathcal{R})$, with $C_{2}$ being the target cluster of this remote view-change.
void GeoGlobalExecutor::Execute(std::unique_ptr<Request> request) {
...
// reset the timer for the region which the request came from.
int region_id = request->region_info().region_id();
if (next_region_ == 1){
TryResetTimer(next_seq_, region_id);
}
else{
TryResetTimer(next_seq_+1, region_id);
}
}
// detect failure of region rvc_target_region in round ρ, trigger RVC
void GeoGlobalExecutor::TriggerRVCLocalBroadcast(int rvc_target_region) {
...
// broadcast drvc_request locally
std::unique_ptr<Request> drvc_request = resdb::NewRequest(
Request::TYPE_DRVC, Request(), config_.GetSelfInfo().id(),
config_.GetConfigData().self_region_id());
drvc_request->set_current_executed_seq(missing_seq);
drvc_request->set_rvc_target_region(rvc_target_region);
replica_client_->BroadCast(*drvc_request);
}
GeoBFT Consensus Service
To process those types of messages we mentioned (geo_request, drvc_request, rvc_request) we need to implement the GeoBFT Consensus Service as the entry for the process of those requests.
int ConsensusServiceGeoPBFT::ConsensusCommit(std::unique_ptr<Context> context,
std::unique_ptr<Request> request) {
switch (request->type()) {
case Request::TYPE_GEO_REQUEST:
return commitment_->GeoProcessCcm(std::move(context), std::move(request)); // Process geo_request
case Request::TYPE_DRVC:
return commitment_->ProcessDRVC(std::move(context), std::move(request)); // Process drvc_request
case Request::TYPE_RVC:
return commitment_->ProcessRVC(std::move(context), std::move(request)); // Process rvc_request
}
return ConsensusServicePBFT::ConsensusCommit(std::move(context), std::move(request)); // Norcal-case PBFT processing
}
int GeoPBFTCommitment::GeoProcessCcm(std::unique_ptr<Context> context,
std::unique_ptr<Request> request) {
... // filter of duplicate message
// if the request comes from another region, do local broadcast
if (sender_region_id != self_region_id) {
std::unique_ptr<Request> broadcast_geo_req =
resdb::NewRequest(Request::TYPE_GEO_REQUEST, *request,
config_.GetSelfInfo().id(), sender_region_id);
replica_client_->BroadCast(*broadcast_geo_req);
}
// push the request into order_queue_
return global_executor_->OrderGeoRequest(std::move(request));
}
int GeoPBFTCommitment::ProcessDRVC(std::unique_ptr<Context> context,
std::unique_ptr<Request> request) {
int missing_seq = request->current_executed_seq();
int rvc_target_region = request->rvc_target_region();
int drvc_sender_id = request->sender_id();
... // filter of duplicate messages
// when receives f+1 DRVC request: detect failure of region C in round
// ρ broadcast DRvc(C, ρ) to all replicas in local region.
int num_replicas = config_.GetReplicaNum();
int max_faulty = (num_replicas - 1) / 3;
if (drvc_map_[std::make_pair(rvc_target_region, missing_seq)].size() == max_faulty + 1) {
global_executor_->TriggerRVCLocalBroadcast(rvc_target_region);
}
// when receives DRvc(C1, ρ) from n − f replicas, send Rvc(C1, ρ)_R to Q ∈ C1, id(R) = id(Q).
if (drvc_map_[std::make_pair(rvc_target_region, missing_seq)].size() == num_replicas - max_faulty) {
std::unique_ptr<Request> rvc_request = resdb::NewRequest(
Request::TYPE_RVC, Request(), config_.GetSelfInfo().id(),
config_.GetConfigData().self_region_id());
rvc_request->set_current_executed_seq(missing_seq);
rvc_request->set_rvc_target_region(rvc_target_region);
... // find target_replica Q
replica_client_->SendMessage(*rvc_request, target_replica);
}
}
int GeoPBFTCommitment::ProcessRVC(std::unique_ptr<Context> context,
std::unique_ptr<Request> request) {
uint64_t missing_seq = request->current_executed_seq();
int sender_id = request->sender_id();
int max_faulty = (config_.GetReplicaNum() - 1) / 3;
... // filter of duplicate messages
// If received f+1 idendical rvc from distinct replicas in C2, trigger local view change.
if (rvc_map_[missing_seq].size() == max_faulty + 1) {
viewchange_manager_->RunTimeoutFunc(missing_seq);
}
// Broadcast rvc locally.
if (request->region_info().region_id() != config_.GetConfigData().self_region_id()) {
std::unique_ptr<Request> rvc_request = resdb::NewRequest(
Request::TYPE_RVC, Request(), config_.GetSelfInfo().id(),
config_.GetConfigData().self_region_id());
rvc_request->set_current_executed_seq(missing_seq);
replica_client_->BroadCast(*rvc_request);
}
}
Preliminary Experiments and Results
Experiment Setup
We ran all the experiments on AWS using:
- t3.2xlarge
- 8 vCPU
- 64GB of RAM
Nexres ran on Ubuntu, 20.04 LTS, amd64 focal image build on 2022-09-14.
Throughput and Latency Performance
The first experiment is designed to test the maximum throughput and latency of GeoBFT and compare the result with PBFT performance under the same configuration. The throughput and latency of PBFT and GeoBFT with 4 clusters with different numbers of replicas are recorded. The replica number is set to 16, 32, 64, and 128.
From the figure below, we can see that as the system scales, the throughput decreases and the latency increases for both PBFT and GeoBFT. With respect to throughput, GeoBFT outperforms PBFT at all replica settings. In general, the average latency of GeoBFT is smaller than PBFT at all replica settings except for the 16-replica setting, and it is almost half of PBFT latency at the 128-replica setting.
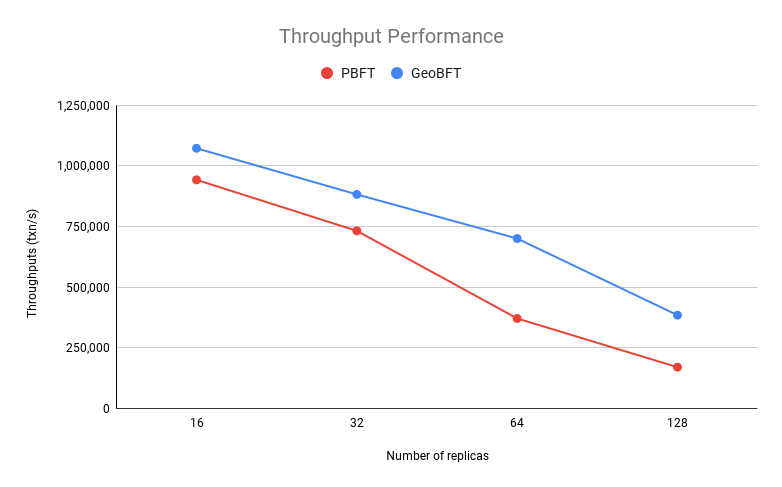
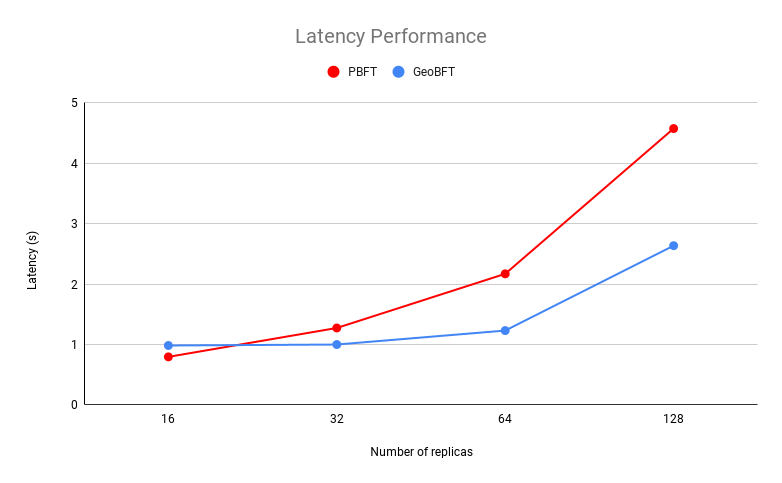
Figure 8. Throughput and latency as a function of the number of replicas.
Impact of Primary Failure
In the second experiment, we measure the performance of GeoBFT when a single primary fails (in one of the two regions). The system configuration is 2 clusters with 16 replicas in each cluster, 32 replicas in total.
Figure 9 shows the throughput attained by GeoBFT when the primary of one cluster fails, and the replicas run the remote view change protocol to replace the faulty primary. The primary of one of the clusters fails at 45s, and the system’s average throughput starts decreasing; Later, GeoBFT again observes an increase in throughput at 60s.
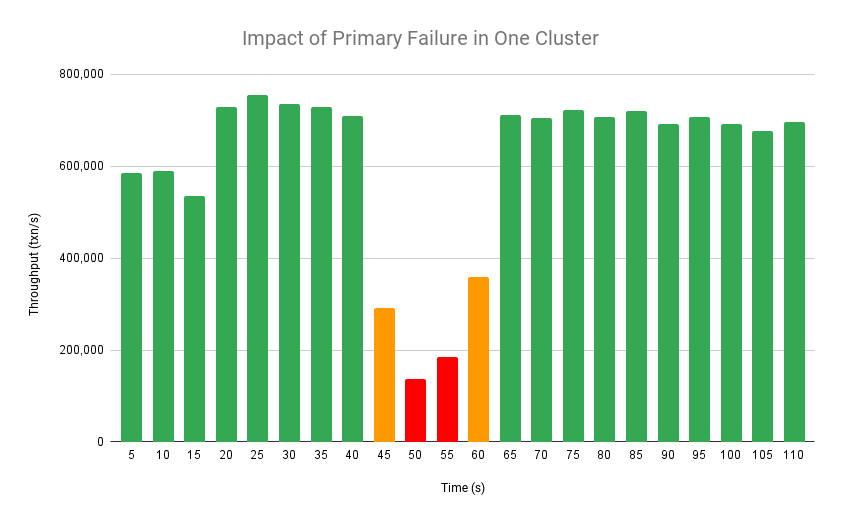
Figure 9. GeoBFT's throughput under the primary failure of one cluster out of two.