What is Raft?
Raft is a consensus protocol used in many existing software systems including Kubernetes, Kafka, and MongoDB. It has been battle-tested in many circumstances since it was first described in 2013. The ResilientDB project on GitHub has had an open issue since October 2023 for Raft to be added to the portfolio of available consensus protocols. We aim to fulfill this feature request.
Raft is a crash fault tolerant (CFT) protocol, and would be the first non-Byzantine fault tolerant (BFT) consensus protocol available within ResilientDB, which does come with benefits. A ResilientDB deployment would be able to function with only 3 replicas instead of the current minimum of 4 replicas. ResilientDB transaction throughput would scale far better with the number of replicas increases due to the preferable asymptotic message complexity of Raft (O(n)) compared to the PBFT family of protocols (O(n2)). The performance overhead of cryptography in the BFT protocols is also quite high, so latency improvements can also be expected while using Raft.
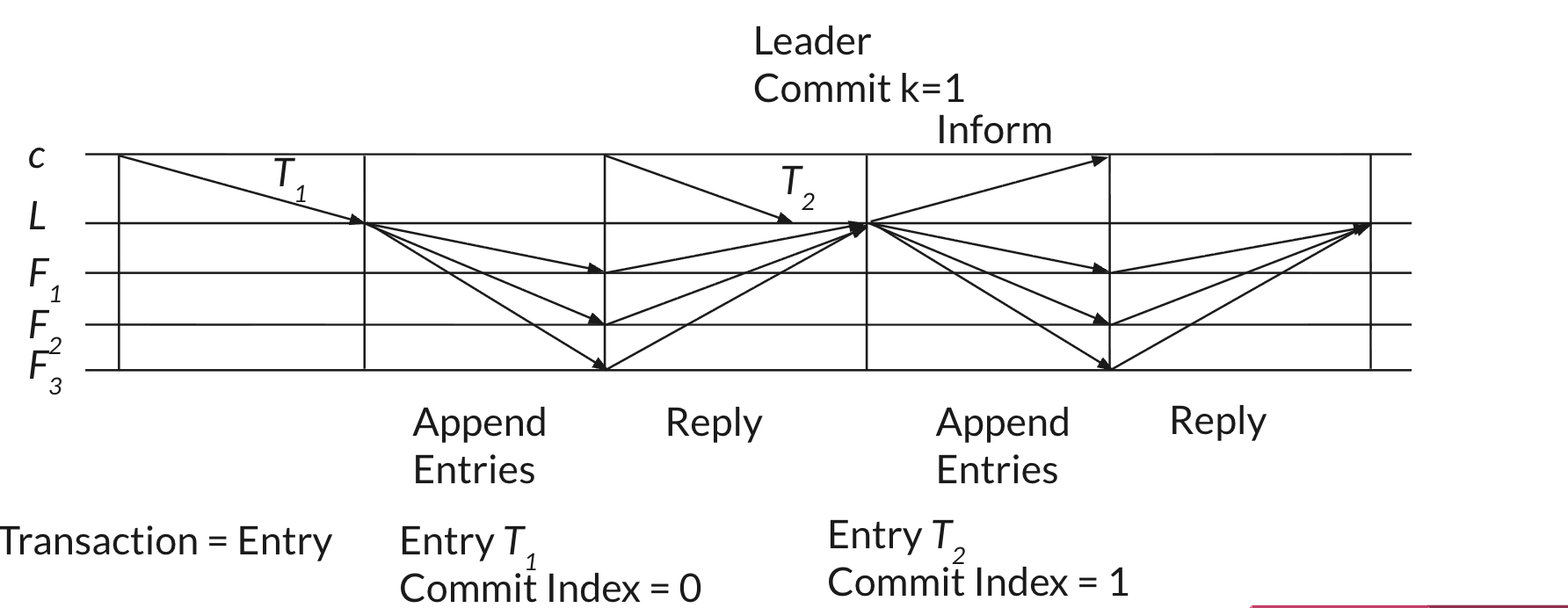
Figure 1. Picture describing Raft Protocol
How It Differs from PBFT

Figure 2. Table comparing Raft vs PBFT
Useful Links
- Official Raft consensus protocol paper: https://raft.github.io/raft.pdf
- Protocol is currently in this repo: https://github.com/hammerface/incubator-resilientdb/tree/raft
Our Implementation Strategy and Architecture
For our implementation, we chose to build on existing consensus protocol code, considering both PBFT and PoE, and ultimately selecting PoE for its simpler and more extensible design. The Consensus class exposes a ProcessCustomConsensus() method that lets us send custom message types through the RPC dispatcher, which in turn allows us to reuse existing components for database access and client notifications via TransactionManager, as well as replica messaging via ReplicaCommunicator. Our approach also benefits from built-in benchmarking support through the PerformanceManager module.
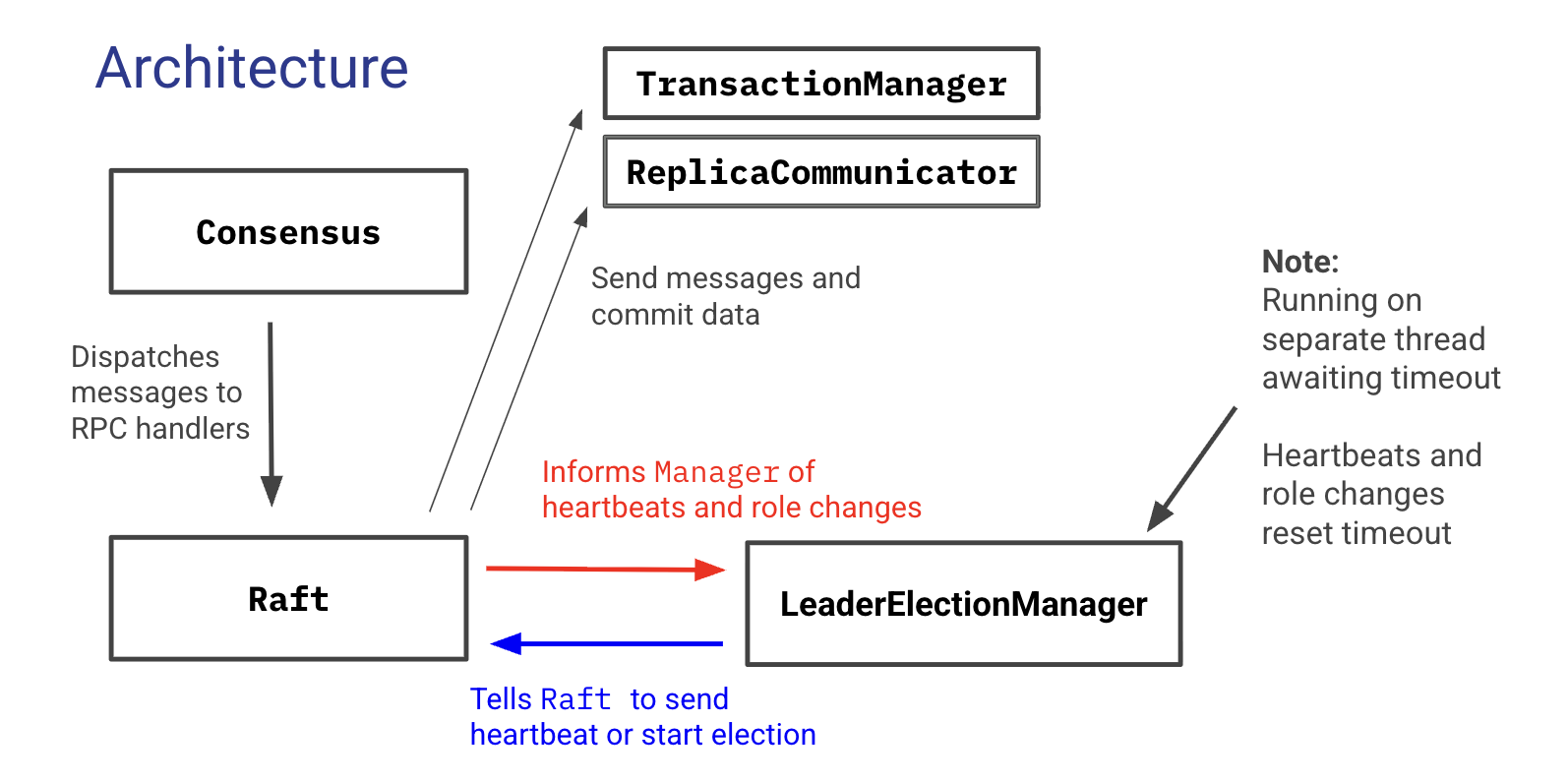
Figure 3. Implementation Architecture
1. Append Entries RPC - Log Replication
In Raft, log replication is driven by the leader: whenever a client sends a command, the leader appends it to its own log and then sends AppendEntries RPCs to followers to copy the new log entries. Followers accept an entry only if it follows a log prefix that matches the leader’s (same term and index), which keeps logs consistent across the cluster. Once a majority of followers have stored an entry, the leader commits it and applies it to the state machine, then notifies followers so they can commit it too. Catchup happens naturally for slow or rebooted followers: the leader keeps sending them AppendEntries starting from their nextIndex until their log matches the leader’s, filling in any missing or outdated entries along the way.
Our Implementation Logs
Figure 4. Append Entries Logs
2. Leader Election
In Raft, leader elections occur when servers do not hear from the current leader within their timeout window. Each server starts as a follower. If a follower doesn’t receive a heartbeat or log entry from a leader within a timeout, it becomes a candidate, increments its term, and asks the other servers for votes. Servers will vote for at most one candidate per term, and they only vote for a candidate whose log is at least as up to date as their own. If a candidate receives votes from a majority, it becomes the new leader and immediately starts sending heartbeats to assert its authority and prevent new elections. If there’s a tie (no one gets a majority), everyone times out again with slightly randomized timers and the election is retried until a leader is chosen.
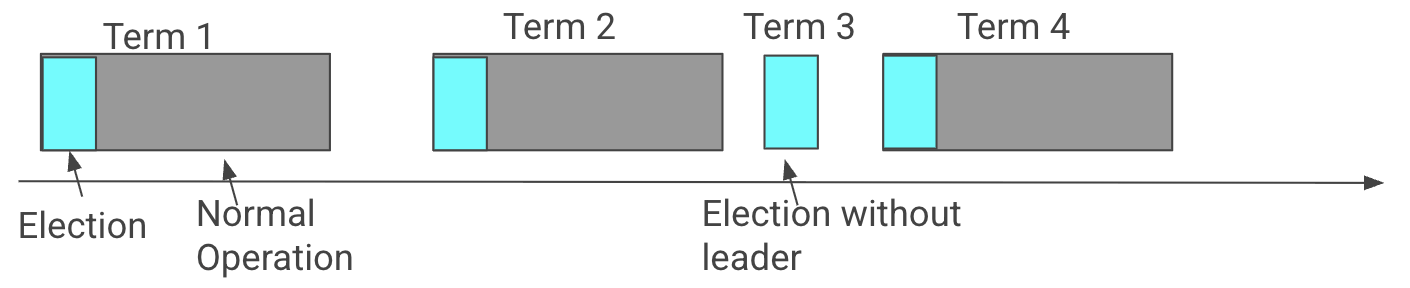
Figure 5. Leader Election Diagram
Our Implementation Logs
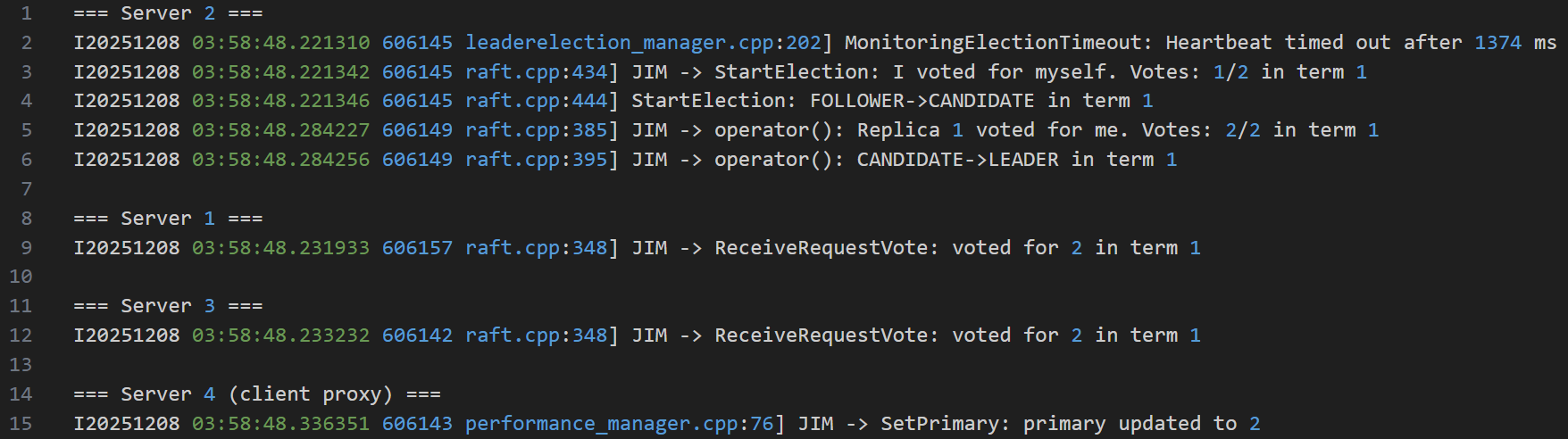
Figure 6. Aggregated Excerpts about Leader Election from the Logs
Commands to Execute
Here are the commands to download Resilient DB, build it, and run the RAFT and PBFT performance scripts:
sudo apt updatesudo apt-get install gitsudo apt install psmiscgit clone https://github.com/apache/incubator-resilientdb.gitcd incubator-resilientdb/./INSTALL.sh./service/tools/kv/server_tools/start_kv_service.shbazel build service/tools/kv/api_tools/kv_service_toolscd scripts/deploy/touch config/key.conf./performance_local/raft_performance.sh config/kv_performance_server_local.conf./performance_local/pbft_performance.sh config/kv_performance_server_local.conf
Benchmarks
Here is our output after running both of the performance scripts, with PBFT results gathered using the main branch:
Note, both configurations have the minimum number of nodes for f = 1 (the client is included as a node, so 4 replicas for PBFT and 3 replicas for Raft).
PBFT:
calculate results, number of nodes: 5
max throughput: 44660
average throughput: 20871.272727272728
max latency: 0.000144599
average latency: 0.000107366275
Raft:
calculate results, number of nodes: 4
max throughput: 104418
average throughput: 45385.2
max latency: 8.15001e-05
average latency: 6.7288925e-05
Raft outperforms PBFT both in terms of throughput and latency, by roughly double. We ran into issues with the leader election with 4 Raft nodes, which we are still looking into.
Looking Ahead
-Batching - Groups multiple client transactions into a single Append Entry RPC to significantly boost throughput and reduce network overhead.
-State Persistence - Saves critical data (current term, vote, and log) related to the protocol itself to stable storage (in ResilientDB).
-Snapshots - Replaces old log entries with a compact file of the current state to prevent the log from consuming all available memory and to allow followers to catch up quicker.
-Membership Changes - Enables the safe addition or removal of servers from the cluster dynamically without shutting down the system or halting operations.
-Inconsistent progress stalls - We appear to have some inconsistencies with the leader elections where the leader is chosen but does not appear to make progress. How often this state occurs seems to vary based on the number of nodes. This needs to be investigated.