ResTier: A Tiered Storage Engine with IPFS Cold Storage for ResilientDB
Exploratory Systems Lab Jun 02, 2026
ResTier is a tiered storage engine for ResilientDB that extends the permissioned blockchain fabric with hot/warm/cold storage tiers, using IPFS as a scalable cold-storage backend. The engine transparently migrates historical data from local storage (MemoryDB or LevelDB) to IPFS, providing unbounded storage growth with zero write-path latency overhead and O(1) cold-read performance via an in-memory secondary index.
Motivation
ResilientDB is a high-throughput permissioned blockchain fabric that orders and executes client transactions through PBFT consensus. By default, all blockchain state, i.e. every key-value pair, every version, is persisted indefinitely in local LevelDB storage. As the ledger accumulates history, storage grows unboundedly: every transaction, every checkpoint, every version remains on disk. For production deployments that process millions of transactions, this increases the costs multifold to vertically scale the number of SSDs for all resilientdb nodes.
Existing storage backends offer no mechanism to offload cold or archival data. Operators face a choice between expensive vertical scaling (larger disks) or manual data pruning, which breaks the blockchain’s immutability guarantees. What is needed is a storage system that can seamlessly migrate historical data to cheaper, scalable storage while keeping recent data on fast local storage—all without changing the application’s query interface or the consensus protocol.
IPFS (InterPlanetary File System) is a natural fit for the cold tier. It is decentralized, content-addressed (CIDs are cryptographic hashes of the data), trustless (content is mathematically verified), provides built-in deduplication, replicates across nodes via peer-to-peer gossip, and carries no vendor lock-in. By combining IPFS with ResilientDB’s existing MemoryDB and LevelDB tiers, we can build a storage engine that is both scalable and transparent.
The key goals of ResTier are:
- Unbounded storage growth: Historical data automatically migrates to IPFS, freeing local disk space.
- Zero write-path overhead: The hot write path is untouched; migration runs asynchronously.
- Transparent cold reads: Applications use the same
GetValueAPI; cold data is fetched from IPFS automatically. - No consensus changes: Each PBFT replica migrates independently; no cross-replica coordination is needed.
Architecture Overview
ResTier organizes storage into two data storage tiers and one index manifest tier that form a hierarchy of decreasing performance and increasing capacity:
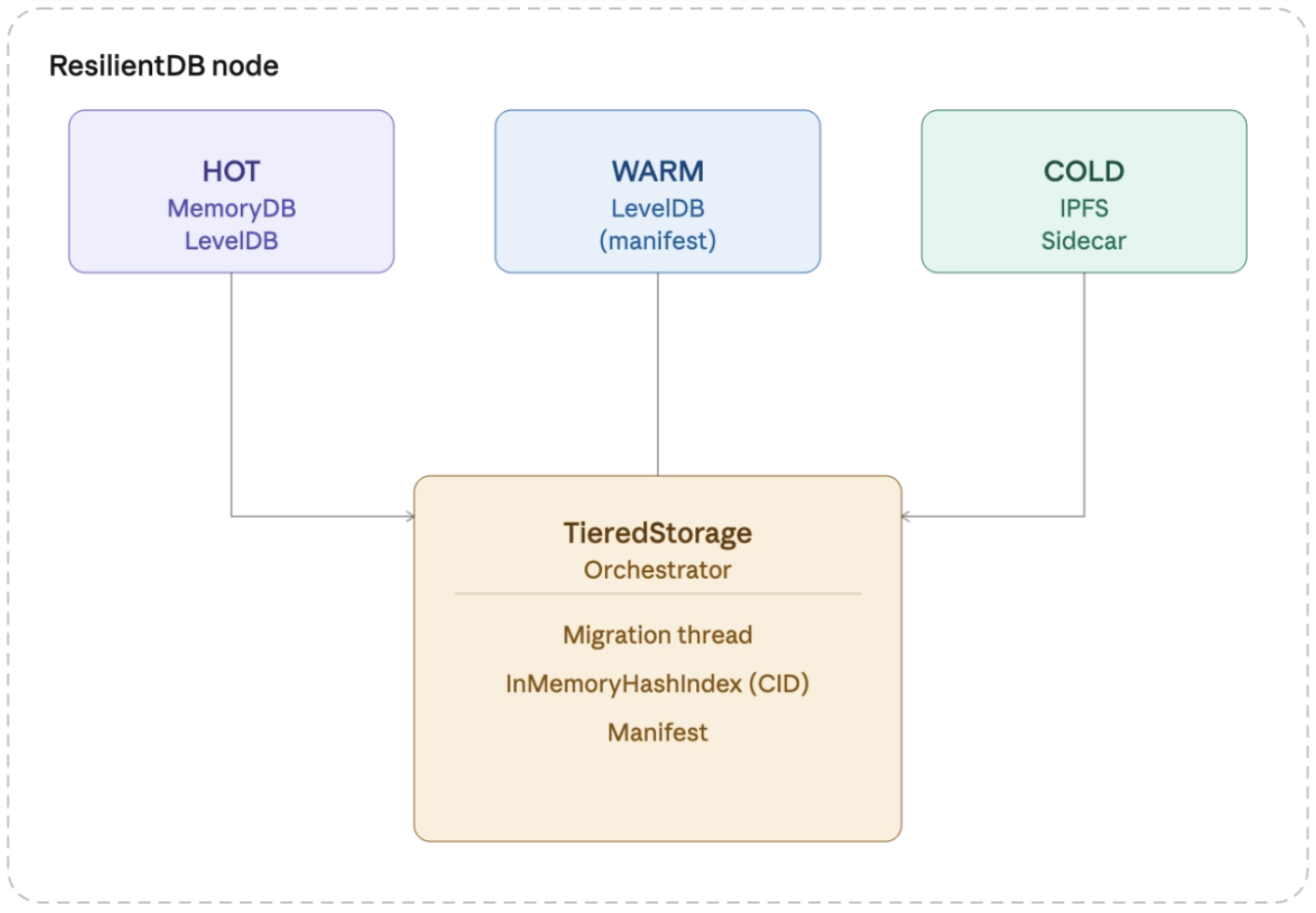
Each PBFT replica runs its own IPFS sidecar and maintains its own manifest index. There is no cross-node coordination for migration—each replica independently decides when and what to migrate. Consensus guarantees that all replicas converge to the same application state regardless of the storage backend.
Four Storage Modes
ResTier supports four deployment modes to accommodate different use cases:
| Mode | Backend | Hot Tier | Warm Tier | Cold Tier | Use Case |
|---|---|---|---|---|---|
| 0 | MEMORYDB | MemoryDB | — | — | Dev/testing, fastest access |
| 1 | LEVELDB | LevelDB | — | — | Production, small datasets |
| 2 | TIERED | LevelDB | LevelDB (manifest) | IPFS | Production, large data |
| 3 | TIERED | MemoryDB | LevelDB (manifest) | IPFS | High-throughput, crash-tolerant |
Modes 2 and 3 are the primary focus. They enable unbounded storage growth by offloading cold data to IPFS while keeping hot data on fast local storage.
Write Path: Zero Overhead by Design
The write path is deliberately kept simple. When a client submits a transaction through PBFT consensus, the execution layer calls TieredStorage::SetValueWithSeq(key, value, seq). This method writes only to the hot storage tier:
Client → PBFT Consensus → KVExecutor → TieredStorage::SetValueWithSeq
│
▼
hot_storage_.SetValueWithSeq
│
▼
MemoryDB or LevelDB (immediate)
│
▼
max_seq_ updated (atomically)
The warm LevelDB (which stores the manifest index) is not touched on the write path. This is a deliberate design decision: writing to LevelDB on every transaction would add 20–50µs of latency. By deferring all manifest updates to the asynchronous migration thread, ResTier ensures that the write-path latency is identical to the underlying hot storage when the tiering were not enabled (memorydb or leveldb).
Checkpoint tracking differs by hot tier:
- LevelDB hot tier: Uses LevelDB’s native
UpdateLastCkpt(seq)mechanism, which fires on every write viaSetValueWithSeq. - MemoryDB hot tier: Tracks
max_seq_atomically as a simple counter. There is no warm-write overhead.
Read Path: Transparent Auto-Fallback
The read path implements a three-level cascade: hot storage is checked first, then warm (LevelDB manifest), and finally cold (IPFS). The fallback is completely transparent to the application:
GetValue(key)
│
├── HOT (MemoryDB/LevelDB) ─── found? ──► Return value
│
└── not found ──► COLD (IPFS)
│
▼
InMemoryHashIndex.Get(key) or WARM (LevelDB Manifest Index) → CID
│
▼
IPFS::Cat(CID)
│
▼
Return value
The cold-read path uses an in-memory secondary index (InMemoryHashIndex, backed by std::unordered_map) to map keys to their IPFS CIDs. Lookups are O(1) here. This is extremely faster than any IPFS network operation, so the index is never the bottleneck.
Benchmark measurements confirm this:
- Hot read (MemoryDB): 2µs p50
- Hot read (LevelDB): 15µs p50
- Index lookup: 1µs p50
- Cold read (IPFS Cat, loopback): 4ms p50 (This latency for historical reads is the tradeoff for cheaper storage. But from the client’s perspective this latency might get hidden because of higher network latency between client -> resilientdb client proxy -> resilientdb nodes)
Migration Flow: Asynchronous Background Thread
Data migration from hot storage to IPFS runs in a background thread inside TieredStorage. This design was chosen over a separate sidecar process because LevelDB’s LOCK file prevents concurrent access from multiple processes.
TieredStorage constructor → StartMigration()
│
▼
If tiering enabled + IPFS available:
├── 1. Create InMemoryHashIndex
├── 2. Load Manifest from warm LevelDB → populate index
Background thread: MigrationLoop() ─ poll every N seconds
│
▼
MigrateColdData()
│
├── 1. Get checkpoint from hot storage
├── 2. Calculate cold threshold: seq <= (checkpoint - watermark × threshold)
├── 3. Scan hot storage via GetAllItemsWithSeq()
├── 4. For each eligible key:
│ ├── Upload to IPFS via POST /api/v0/add → get CID
│ ├── Add CID to InMemoryHashIndex
│ ├── Save manifest to warm LevelDB
│ ├── Delete key from hot storage
│ │ └── (LRU cache invalidated for LevelDB hot tier)
│ └── Unpin stale CID in case of value updates to existing key to prevent bloating in IPFS due to stale data
│
└── 5. Sleep until next poll interval
Key Design Decisions
Cursor optimization (last_migrated_seq_): On each migration cycle, only keys with sequence numbers between last_migrated_seq_ and the cold threshold are eligible. This avoids a full scan of the hot storage on every cycle. The cursor is persisted to warm storage after each successful cycle, so crash recovery resumes from the last saved position rather than scanning from seq 0.
Safe delete with DeletableStorage interface: Deletion from the hot tier is mediated through a pure virtual DeletableStorage interface. TieredStorage uses dynamic_cast<DeletableStorage*> to check whether the hot storage backend supports deletion at runtime. This avoids friend class coupling and remains extensible to future backends.
LRU cache invalidation: When operating in LevelDB→IPFS mode (Mode 2), the hot tier has an LRU block cache. After DeleteKey removes a key from LevelDB, block_cache_->Remove(key) is called to ensure stale cache entries don’t serve pre-migration values. This bug was caught and fixed during testing.
Race Condition Safety (Concurrent Reads During Migration)
The migration thread operates concurrently with read requests. Four possible race windows were analyzed:
| Window | State | GET Behavior | Safe? |
|---|---|---|---|
| After IPFS upload, before index add | Data in IPFS + hot, NOT in index | Hits hot → correct | ✅ |
| After index add, before hot delete | Data in IPFS + index + hot | Hits hot → correct | ✅ |
| After hot delete | Data in IPFS + index only | Index lookup → CID → IPFS Cat | ✅ |
A stress test with 10 concurrent readers, 100 keys, and 60 seconds of continuous reads during active migration cycles confirmed zero mismatches in both Mode 2 and Mode 3.
Secondary Index Design
The secondary index (manifest) tracks where each key resides in IPFS and provides the CID needed for cold-data retrieval. It is stored in two places:
- In-memory:
InMemoryHashIndexbacked bystd::unordered_mapfor O(1) lookups. - Persisted: A LevelDB manifest database (
<db_path>_manifest_db) that is written after each successful migration cycle and loaded on startup.
The manifest maintains range mappings for efficient range queries:
message IndexManifest {
message RangeMapping {
string start_key = 1;
string end_key = 2;
string ipfs_cid = 3;
uint64 min_checkpoint = 4;
uint64 max_checkpoint = 5;
}
repeated RangeMapping range_mappings = 1;
uint64 total_keys = 2;
uint64 cold_keys = 3;
int64 last_updated_timestamp = 4;
}
The index is stored in the warm LevelDB using reserved key patterns:
| Key Pattern | Description |
|---|---|
_tiered_manifest |
IndexManifest proto with range mappings |
_last_migrated_seq |
Persisted migration cursor for crash recovery |
_migration_status |
Last migration timestamp |
Crash Recovery
On restart, TieredStorage rebuilds the InMemoryHashIndex from the persisted manifest in warm LevelDB. This ensures that all previously migrated keys remain accessible via IPFS even though the in-memory index was lost.
Four crash scenarios are handled:
-
Crash before manifest save: The orphan CID in IPFS is harmless (pinned data with no index entry). On restart, the key is re-migrated—the
GetIndexCIDcheck prevents re-upload since the old CID is not in the rebuilt index. -
Crash after manifest save, before hot delete: The key exists in both hot storage and IPFS. On restart,
GetIndexCID(key)returns the CID, so migration skips this key. GET returns the value from hot storage (correct, same value exists in both tiers). -
Crash after hot delete: The key exists only in IPFS. The manifest is intact, so cold reads work normally.
-
Crash during migration, LevelDB block cache: The block cache is process-local and lost on crash. No stale entries survive restart.
In all cases, zero data loss is guaranteed. At worst, a key exists in multiple tiers (safe duplicate).
Benchmark Results
All benchmarks were run with 4 PBFT replicas and 1 client proxy on localhost, with IPFS daemon on loopback (127.0.0.1:5001). Timers are inserted at the storage layer using std::chrono::high_resolution_clock.
All values in microseconds (µs) unless noted:
| Mode | Metric | 100 Keys (p50/p95/p99) | 1000 Keys (p50/p95/p99) |
|---|---|---|---|
| 0 MemoryDB | Write | 1 / 3 / 6 | 1 / 3 / 5 |
| Read | 2 / 2 / 3 | 2 / 3 / 4 | |
| 1 LevelDB | Write | 23 / 39 / 185 | 23 / 43 / 64 |
| Read | 15 / 30 / 42 | 17 / 30 / 47 | |
| 2 LevelDB→IPFS | Hot write | 24 / 71 / 141 | 26 / 62 / 106 |
| Hot read | 15 / 31 / 42 | 18 / 30 / 50 | |
| Index lookup | 1 / 3 / 4 | 1 / 3 / 4 | |
| IPFS Add | 36752 / 60610 / 74283 | 33586 / 56612 / 67585 | |
| Cold read | 4212 / 11257 / 12525 | 3878 / 5351 / 5668 | |
| 3 MemoryDB→IPFS | Hot write | 1 / 2 / 5 | 1 / 3 / 6 |
| Hot read | 2 / 2 / 3 | 2 / 3 / 4 | |
| Index lookup | 1 / 3 / 4 | 1 / 3 / 4 | |
| IPFS Add | 35241 / 58970 / 78638 | 35074 / 38556 / 55948 | |
| Cold read | 4341 / 5932 / 6106 | 4135 / 5537 / 6639 |
Key Findings
-
Tiering adds zero hot-path overhead: Mode 0 vs Mode 3 and Mode 1 vs Mode 2 show identical hot write and read latencies. The
TieredStoragewrapper delegates directly to the underlying hot storage with no measurable overhead. -
Index lookup is not a bottleneck: At 1µs p50, index lookups are 1000–37000× faster than any IPFS operation. The
std::unordered_mapprovides O(1) lookups regardless of key count. -
IPFS Add dominates migration: At ~35ms per key, IPFS upload is the bottleneck by two orders of magnitude. This is expected—IPFS is a content-addressed storage network, not a local filesystem. For bulk migration, batching and parallelism would improve throughput.
-
Cold reads are viable for archival: At ~4ms on loopback IPFS, cold reads are acceptable for infrequent access to historical data. In geo-distributed deployments, expect 50–200ms depending on network topology.
-
MemoryDB is 23× faster than LevelDB for writes: 1µs vs 24µs p50. Mode 3 (MemoryDB→IPFS) provides the best write throughput while retaining the ability to offload cold data.
Configuration
ResTier is configured via JSON protobuf messages in the server config file. Here is an example for Mode 3 (MemoryDB→IPFS):
{
"storage_config": {
"backend": 2,
"ipfs_info": {
"api_endpoint": "127.0.0.1:5001",
"enabled": true,
"gateway_endpoint": "127.0.0.1:8080",
"timeout_ms": 30000,
"max_retries": 3
},
"tiered_info": {
"cold_threshold_checkpoint": 2,
"enabled": true,
"poll_interval_seconds": 5,
"batch_size": 10,
"auto_migration_enabled": true,
"hot_backend": 0
}
}
}
Configuration Parameters
| Parameter | Default | Description |
|---|---|---|
backend |
0 (MEMORYDB) | Storage mode: 0=MEMORYDB, 1=LEVELDB, 2=TIERED |
hot_backend |
0 (MEMORYDB) | Hot tier when backend=TIERED: 0=MEMORYDB, 1=LEVELDB |
cold_threshold_checkpoint |
2 | Checkpoints to wait before data becomes eligible for migration |
poll_interval_seconds |
60 | How often the migration thread checks for eligible data |
batch_size |
1000 | Maximum keys migrated per cycle |
auto_migration_enabled |
false | Enables the background migration thread |
api_endpoint |
— | IPFS Kubo API endpoint (e.g., 127.0.0.1:5001) |
How to Build and Run
Prerequisites
- Ubuntu 20+ with Bazel installed
- Docker (for IPFS Kubo container)
- LevelDB support: build with
--define enable_leveldb=True
Step 1: Start IPFS Daemon
docker run -d --name ipfs-test -p 5001:5001 -p 8080:8080 -p 4001:4001 ipfs/kubo:latest
Step 2: Build
bazel build //service/kv:kv_service //service/tools/kv/api_tools:kv_service_tools \
--define enable_leveldb=True
Step 3: Generate Certificates
./service/tools/kv/server_tools/generate_keys_and_certs.sh
Step 4: Start the Cluster
The checkpoint watermark is hardcoded to 5 (every 5 transactions triggers a checkpoint). With cold_threshold_checkpoint: 1, data becomes eligible for migration after ~10 transactions.
# Start 4 replicas + 1 client proxy
nohup bazel-bin/service/kv/kv_service service/tools/config/server/server_tiered.config \
service/tools/data/cert/node1.key.pri service/tools/data/cert/cert_1.cert > server0.log 2>&1 &
# ... repeat for nodes 2-4 and client proxy (node 5)
Step 5: Write and Verify
# Write data
for i in $(seq 1 15); do
bazel-bin/service/tools/kv/api_tools/kv_service_tools \
--config service/tools/config/interface/service.config \
--cmd set --key "test_$i" --value "val_$i"
done
# Wait for migration (sleep 10 seconds), then read cold data
bazel-bin/service/tools/kv/api_tools/kv_service_tools \
--config service/tools/config/interface/service.config \
--cmd get --key test_1
# → returns "val_1" (served from IPFS after migration)
Next Steps
ResTier is fully functional and validated for small-to-medium (100k) key counts. The following enhancements are planned:
-
Configurable checkpoint watermark: Currently hardcoded to 5 in
platform/config/resdb_config.h. Making it configurable viaTieredStorageConfigwill allow predictable migration behavior across deployment environments. -
Access-based tiering: Evict based on LRU access patterns instead of checkpoint age.
-
Compression: Compress data before IPFS upload to reduce cold storage costs.
-
Multi-node consistency verification: Validate that all PBFT replicas converge to identical state after independent migration.
Conclusion
ResTier demonstrates that tiered storage with IPFS cold storage can be integrated into a PBFT-based permissioned blockchain with zero write-path overhead and transparent read-path fallback. The architecture—background migration thread, O(1) in-memory secondary index, four storage modes, and interface-based hot eviction—provides a solid foundation for unbounded storage growth in ResilientDB deployments.
The system has been validated through extensive testing: end-to-end migration cycles, cold and hot reads, concurrent reads during migration (zero mismatches), crash recovery, LRU cache invalidation, stale-CID deduplication on key updates, and latency benchmarks across all four modes. ResTier is ready for production evaluation in large-scale ResilientDB deployments.
| *Built on Apache ResilientDB | IPFS Kubo | PBFT Consensus* |
This work is licensed under a Attribution-NonCommercial 4.0 International license.